上个月,组里进行论文学习的时候我给大家讲的是 Faster R-CNN,为了不白看论文,我决定重新组织一下自己对这个模型的了解,顺便写一篇 Blog。
Detection
什么是 Detecion ?与 Detection 相关的 Classification 和 Segmentation 呢?
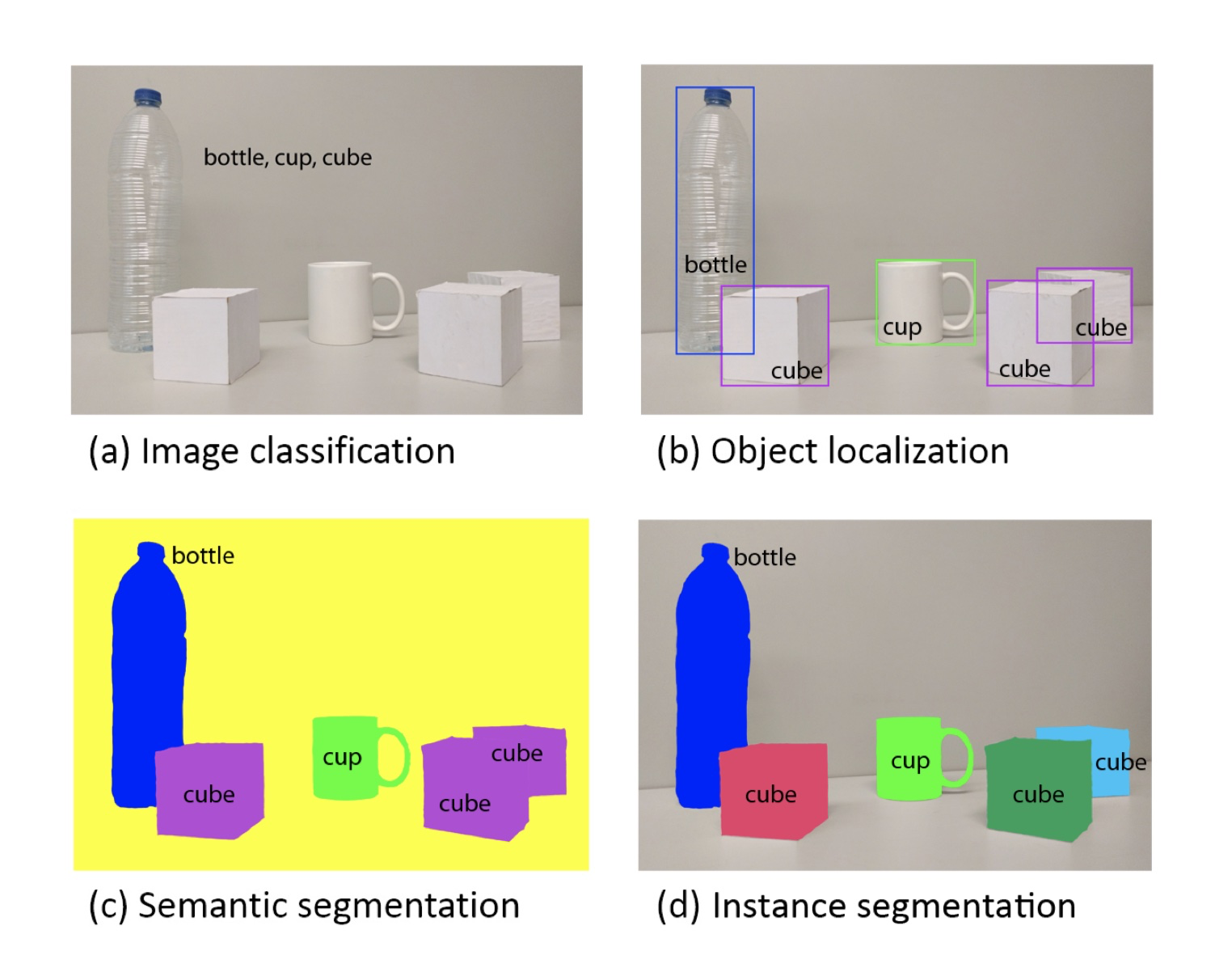
看上图[1],子图 (a) 的情况就是Classification,对于输入的图片只给出了图里存在的物品类别;子图(b)则相对于 (a) 来说,不仅给出了类别还给出了这个物品的位置,这就是 Object Detection;子图 (c)、(d) 则是 Segmentaion 的两个方向,这里不做细说。
知道了 Detection 是什么后,我们来说说 CV 领域关于 Detection 的发展方向。首先,Detection 的主要问题是:图里有什么(Classification),物体具体在图的哪里且大小如何(Localization)。
Detection 有两个方向解决上面提到的两个问题:
第一种 One-Stage
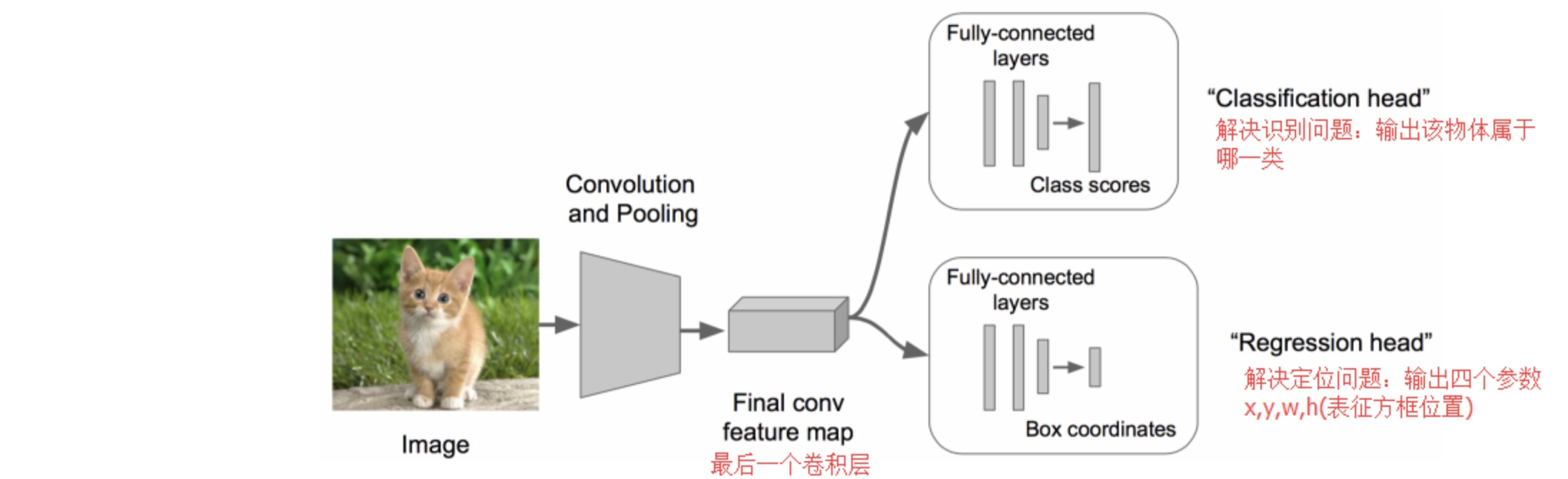
这个方法使用 Regression 的思路。普通 Classification 能获取物体的类别但是不知道位置,那么既然能知道类那能不能也知道位置呢?于是基于普通的 Classification 在某个 Feature Map 的基础上兵分两路,一路是 Classification(原来的路径),另一路则利用 Regression 通过 Feature Map 获得 Localization 需要的东西——坐标。
其简单结构可以看下图。
第二种 Two-Stage
这种办法与 One-Stage 不同在,它先需要先产生多个 Localization 需要的坐标,然后再逐一判断每个坐标对应的候选框哪个“最好”。
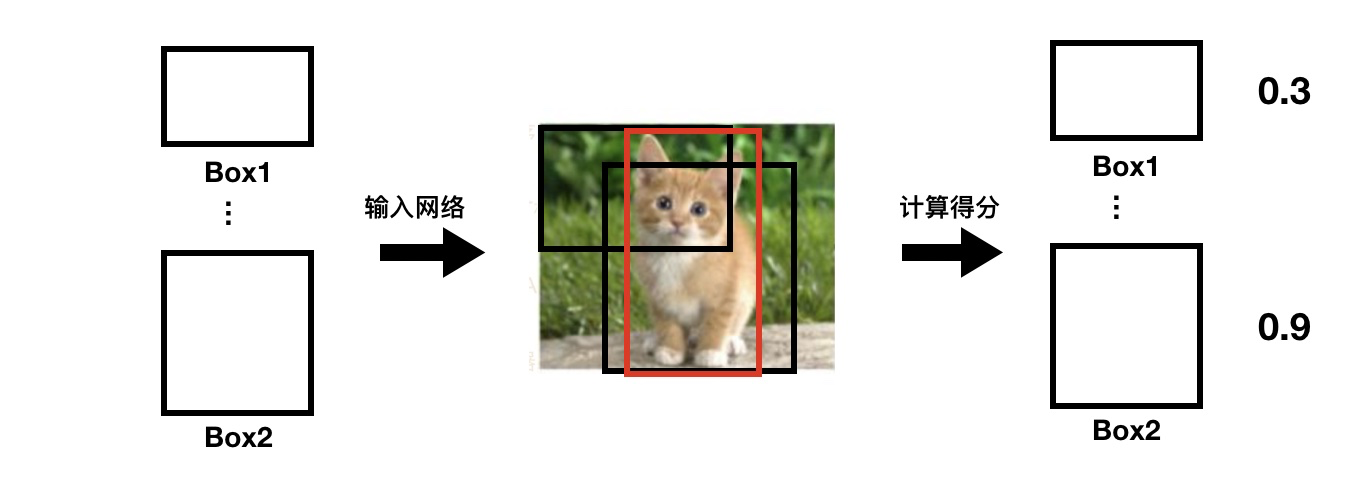
当然,产生的坐标方式有很多,最笨的办法是暴力枚举。好的办法当然有,比如本文讲的 Faster R-CNN 的鼻祖——RCNN。
R-CNN 和 Fast R-CNN
R-CNN[2]
比暴力好的办法当然有,R-CNN 就算一个。
R-CNN 的具体过程:
-
利用图片本身来获取一些物体可能存在的候选区域(Region Proposal)其中,候选区域使用 Selective Search[3] 算法。
注意:通过 Selective Search 获取候选区域后会有一个小问题,就是候选区域的大小都是不同的,于是需要利用缩放将所有候选区域统一到一个大小(论文中为227)。这样,就可以得到统一的、可以放入 CNN 的候选区域了。
-
对于这些统一的候选区域,通过 CNN 做一次 forward 计算,就可以得到 Feature Map 了,这样可以继续后面的操作。
同时,这些候选区域根据 Ground Truth 通过 NMS 方法过滤大部分无用的候选区域,且为有用的候选区域确定其对应的类别标签。
-
对于这些 Feature Map 以及其对应的类别标签,我们把他们送入各个类的类别分类器(论文中为 SVM,且有20个分类器)进行训练。当测试时,遍历这些 SVM 来判断其是否属于该类。由于负样本很多,使用hard negative mining 方法。
-
对于这些 Feature Map 以及其对应的 Ground Truth,再利用 Regression 进行训练。测试时,获取候选框的修正量,以便获取更为准确的候选框。
Fast R-CNN[4]
但是,R-CNN 有两个明显的问题:
- 输入特征提取网络 CNN 的候选区域是固定大小的,为了统一大小而进行的操作 crop 和 warp等,都会导致各种问题(crop 导致可能无法包括整个物体;wrap 导致因为形变而丧失几何结构信息)。
- 候选区域的数量很多,相互之间的重叠也很严重,存在大量的无用计算,耗费时间很长。
为了解决第上面两个问题,提出了 Fast R-CNN。
讲 Fast R-CNN 之前要先讲讲 Fast RCNN 借鉴的一个重要方法 SPPNet[5] 。
SPPNet
SPPNet 的提出主要是解决 R-CNN 的第一个问题,即输入固定的问题。
研究 “图片 --> 卷积层 --> 全连接层” 这个结构,你会发现 “图片 --> 卷积” 这个结构尺寸匹配没有问题,有问题在于之后的 “卷积层 --> 全连接层” 这个结构。
那么,解决这个问题有两个方法:
- 不动全连接层,采取其他手段保证全连接层的输入的尺寸固定。
- 搞定卷积层的输出,使其统一大小。
SPPNet 选择第二种办法,通过 SPP (Spatial Pyramid Pooling) 这个结构解决了输入固定的问题。
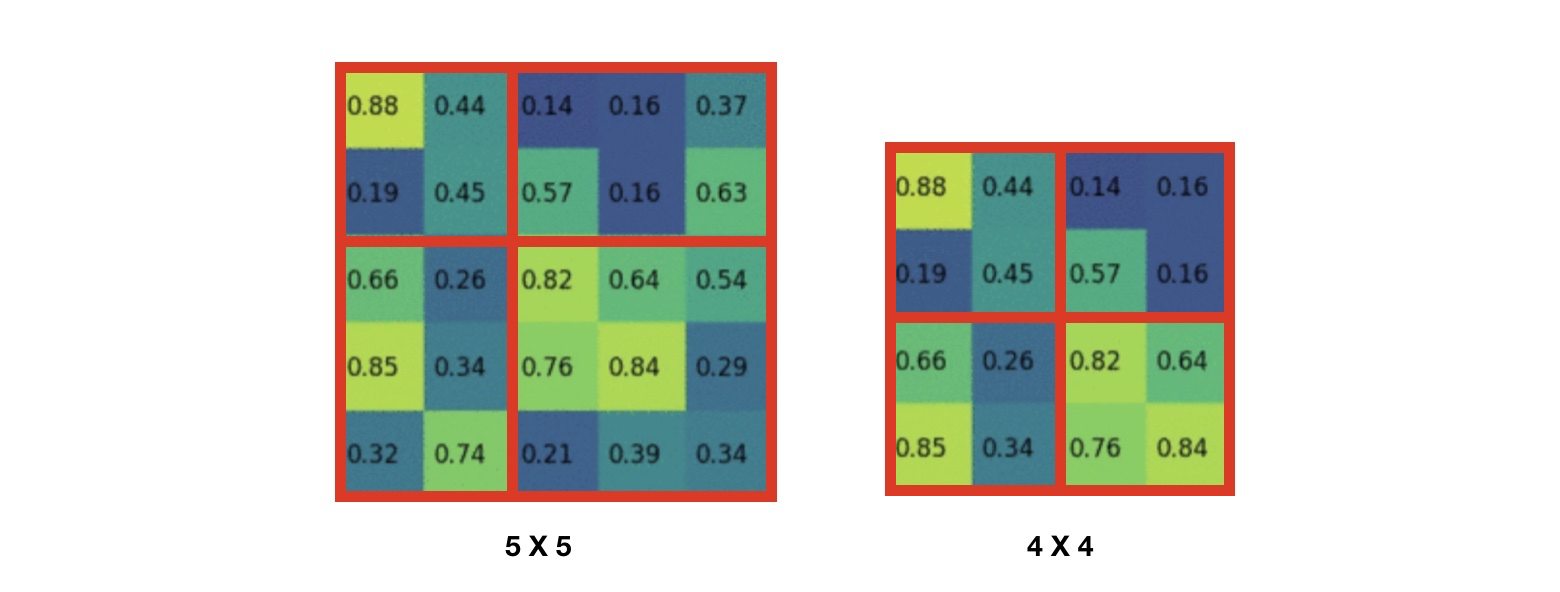
具体结构如下图
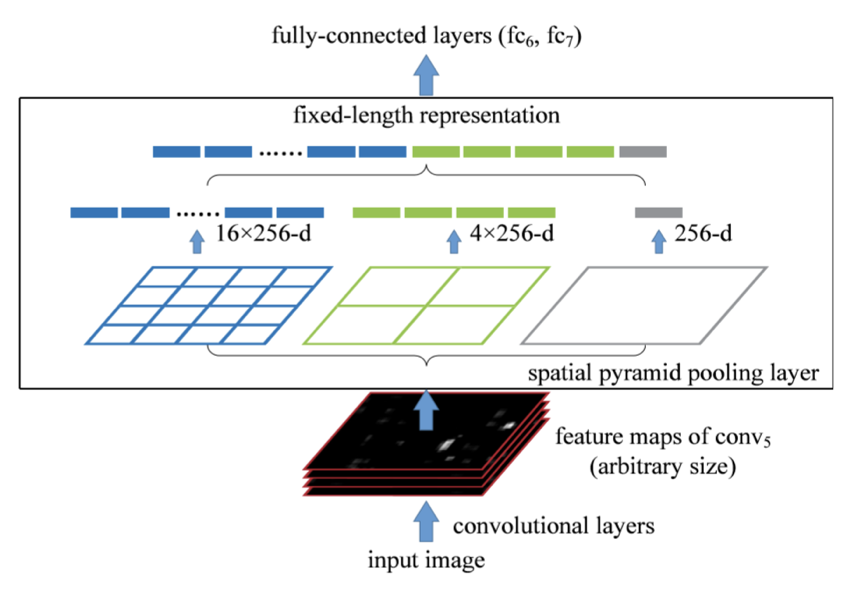
框内的结构就是 SPP 。可以明显看出,对于 SPP 的输入(卷积层的结果),使用3种尺度的 pooling 层来获得固定的输出,具体来说(以中间为例),对于卷积层的结果先经过第一个pooling层,获得 的固定输出(例子如下图),同理可以获得 和 的结果,于是将其展开可以获得估计为 21 的输出()。
Fast R-CNN 的具体过程
有了 SPPNet 的结构的基础,才有了 Fast R-CNN 的提出。
与 R-CNN 相比,Fast R-CNN 有两点改进:
- 使用了 ROI Pooling,这是 SPP 结构的变体;
- 使用了多分类,取代了 SVM 分类。
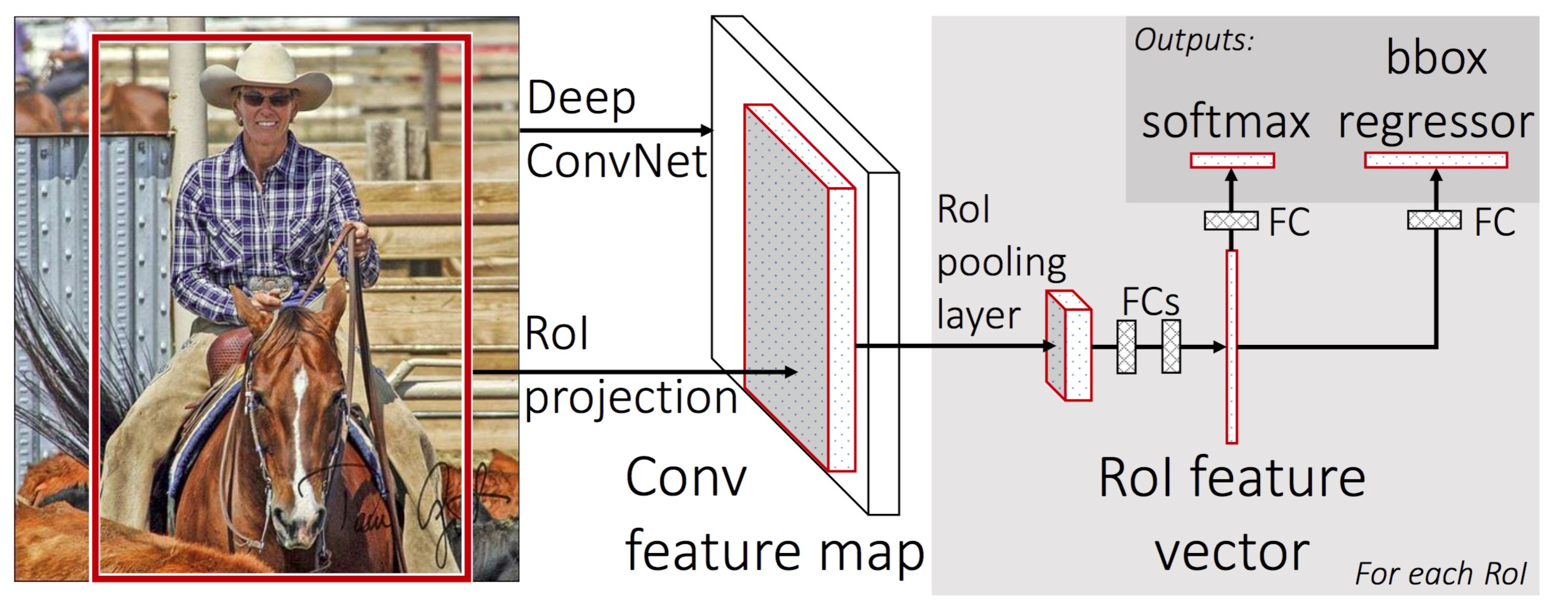
具体过程:
- Fast R-CNN 和 R-CNN 一样对图片使用 Selective Search 提取 Region Proposal;
- 其次再把图片放入神经网络提取 Feature Map。
- 将 Region Proposal 映射到 Feature Map 上提取 Region Proposal 对应的 子 Feature Map;
- 子 Feature Map 送入 ROI Pooling,再经过全连接层;全连接层的输出有以下两条路:
- 加上其对应的类别标签进行多分类器的训练。测试时,通过多分类获得类别。
- 加上其对应的 Ground Truth 进行回归器的训练。测试时,通过回归器获得坐标的修正参数。
对于这个 ROI Pooling,其实就是 SPP 的变体,其不再是多个 Pooling 层,而是只有一个 Pooling 层。
结构可见下图:
 至此,Fast R-CNN 的训练过程结束。
至此,Fast R-CNN 的训练过程结束。
A Review on Deep Learning Techniques Applied to Semantic Segmentation,Fig 1 ↩︎
R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014. ↩︎
J. Uijlings, K. van de Sande, T. Gevers, and A. Smeulders.Selective search for object recognition. IJCV, 2013. ↩︎
R. Girshick, “Fast R-CNN,” in IEEE International Conference on Computer Vision (ICCV), 2015. ↩︎
K. He, X. Zhang, S. Ren, and J. Sun, “Spatial pyramid pooling in deep convolutional networks for visual recognition,” inEuropean Conference on Computer Vision (ECCV), 2014. ↩︎